
Data-Driven Modeling and Optimal Control for Plasma Systems
Data-Driven Modeling and Optimal Control for Plasma Systems
Plasma control is one of the central challenges in fusion energy research. A fusion plasma must be hot enough, dense enough, and confined long enough to sustain useful reactions, but the plasma state is shaped by many coupled physical processes. Heating, current drive, magnetic equilibrium, plasma shape, kinetic effects, and instabilities all interact with one another.
This makes plasma operation a difficult control problem. The goal is not simply to maximize one quantity. A useful plasma scenario must satisfy several constraints at the same time: maintaining stability, reaching target plasma parameters, avoiding operational limits, and reducing unwanted fluctuations or instabilities. Because of this, trial-and-error experimental optimization is expensive and inefficient.
This research explores how data-driven modeling, reinforcement learning, and optimal control can be used to design intelligent control strategies for plasma systems. The central idea is to combine physics-based simulation or data-driven plasma models with learning-based controllers that can discover effective control policies through interaction with the plasma environment.
Two related directions are considered:
- Tokamak plasma operation control, where a data-driven KSTAR simulator is used with multi-objective reinforcement learning.
- Kinetic instability suppression, where reinforcement learning is used to control an external electric field in a Vlasov-Poisson plasma.
Although these two problems occur at different physical regimes, they share the same control philosophy: learn how to steer a complex plasma system toward a more desirable dynamical state.
Why Reinforcement Learning for Plasma Control?
Plasma dynamics are nonlinear, high-dimensional, and often difficult to model accurately from first principles alone. In tokamak operation, many plasma quantities evolve together under actuator constraints. In kinetic plasma systems, wave-particle interactions can produce instabilities that grow rapidly and change the phase-space structure of the distribution.
Classical control approaches are powerful when accurate reduced models or linearized dynamics are available. However, many plasma-control problems involve regimes where the governing dynamics are only partially known, expensive to simulate, or too complex for direct optimal control.
Reinforcement learning provides a useful framework for this type of problem. Instead of requiring an explicit closed-form solution of the control law, the controller learns from interaction with an environment. The environment may be a data-driven simulator, a physics-based solver, or eventually an experimental device. The learned policy maps the observed plasma state to a control action.
In this research, reinforcement learning is used not merely as a black-box optimizer, but as a computational tool connected to optimal control. The controller is trained to improve a reward or cost functional that reflects the physical objective: tracking desired plasma parameters, reducing instability growth, or minimizing control effort.
Tokamak Plasma Operation Control with a Data-Driven KSTAR Simulator
The first direction focuses on tokamak plasma operation control. In steady-state tokamak operation, several physical quantities must be controlled simultaneously. Examples include poloidal beta, safety factor, plasma current, boundary shape, and other equilibrium-related parameters.
Previous studies have explored beta control, plasma shape control, and multi-parameter control using reinforcement learning. However, controlling multiple plasma parameters is naturally a multi-objective problem. Different quantities may have different time scales, different physical constraints, and competing operational requirements. Improving one objective may not always improve another.
Therefore, instead of treating multi-target control as a simple weighted sum of individual rewards, this work approaches tokamak operation control through the perspective of multi-objective reinforcement learning.
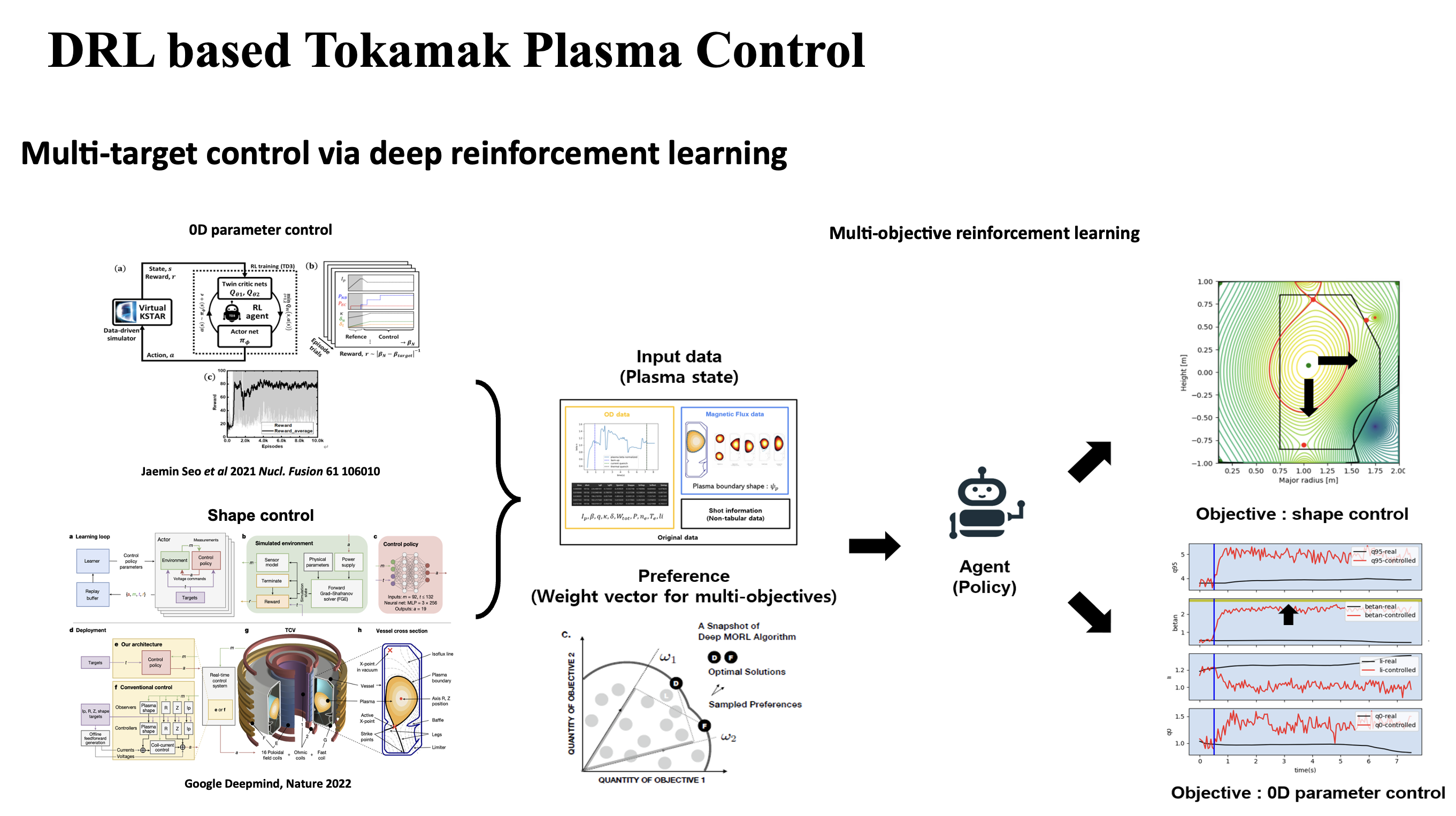
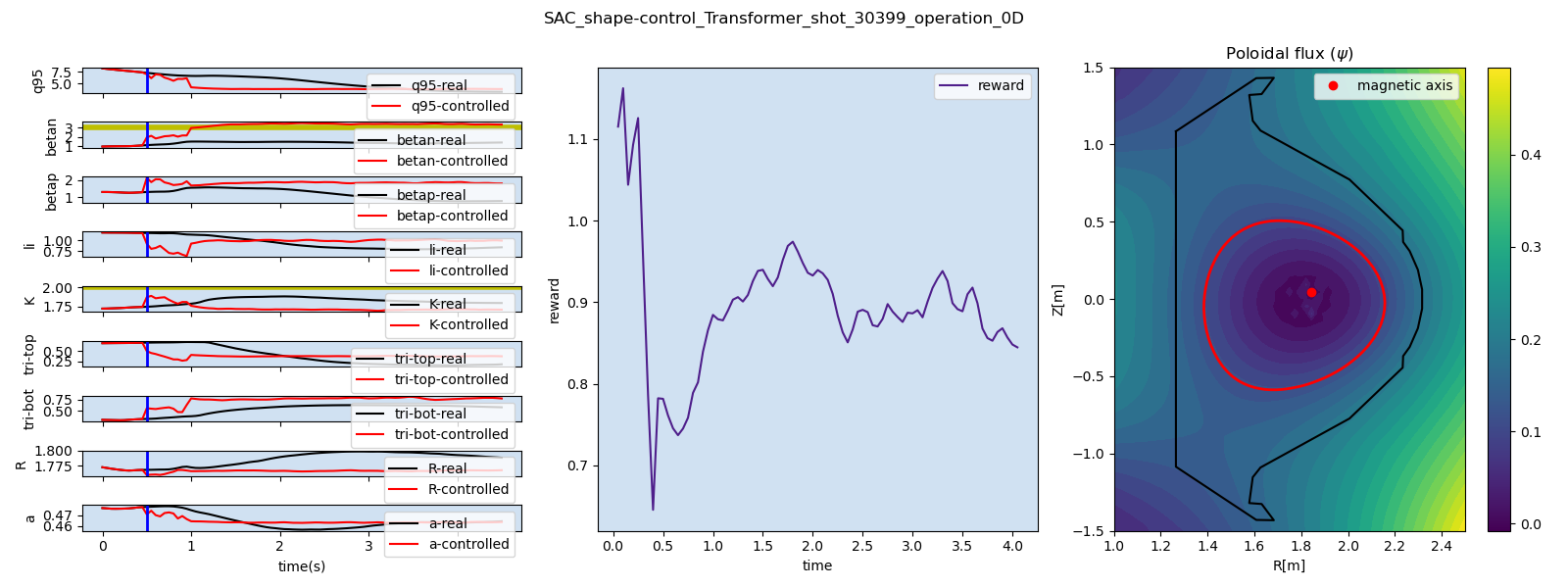
The overall framework uses a virtual KSTAR environment that approximates the plasma response to external control actions. The control variables include heating sources such as NBI and EC heating, shape parameters, plasma current, and toroidal magnetic field. The target quantities are based on EFIT parameters.
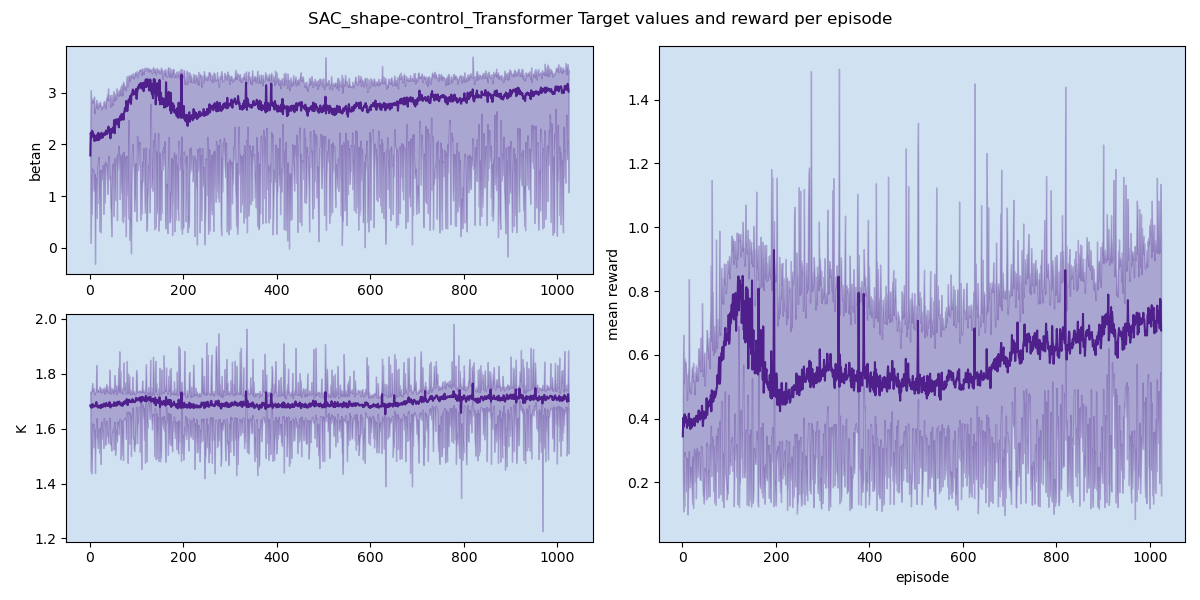
The purpose of the virtual environment is to allow the reinforcement-learning agent to explore plasma-control strategies without relying directly on expensive experimental trials. The agent receives the predicted plasma state, applies a control action, and learns how the plasma responds over time.
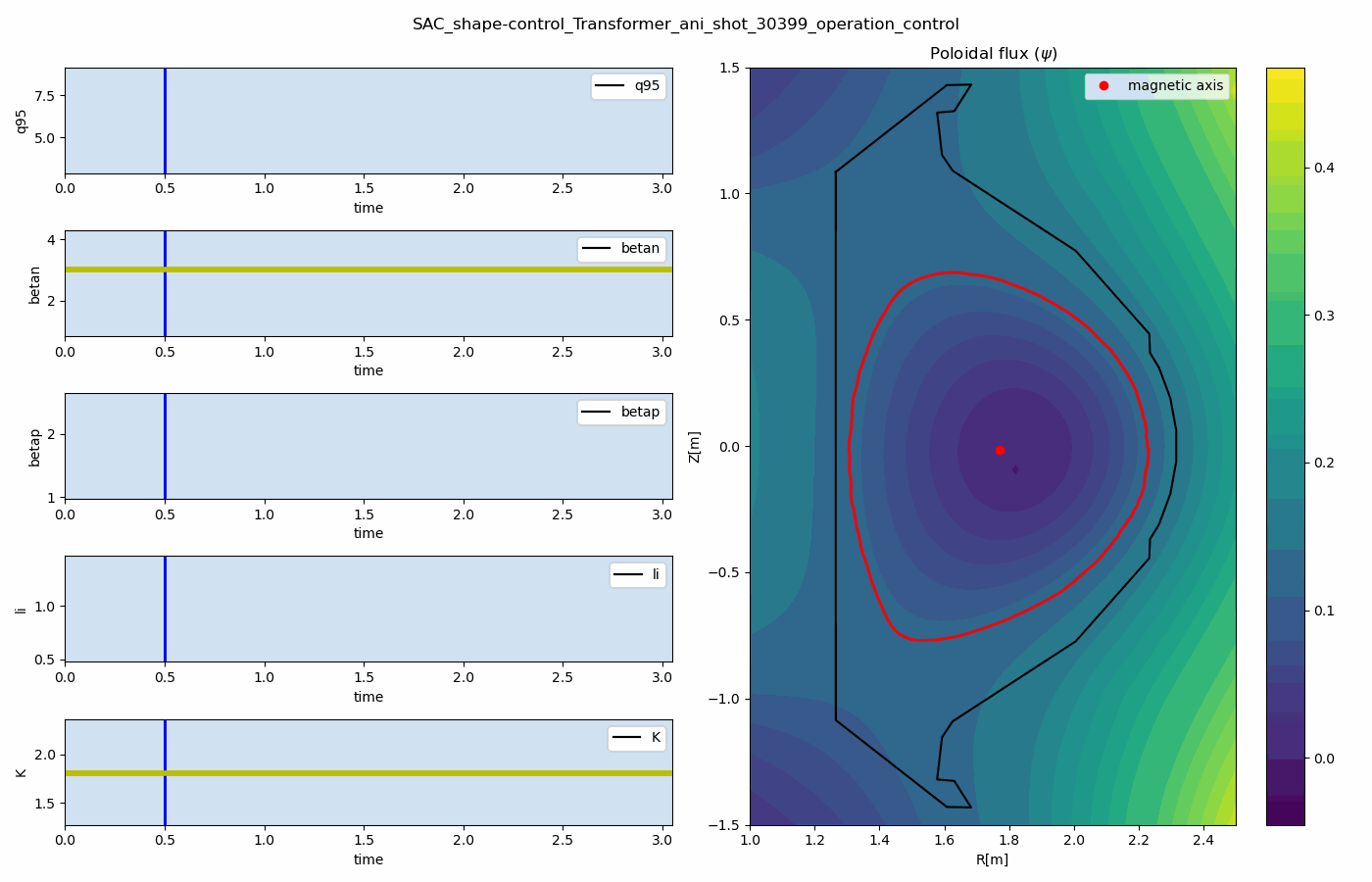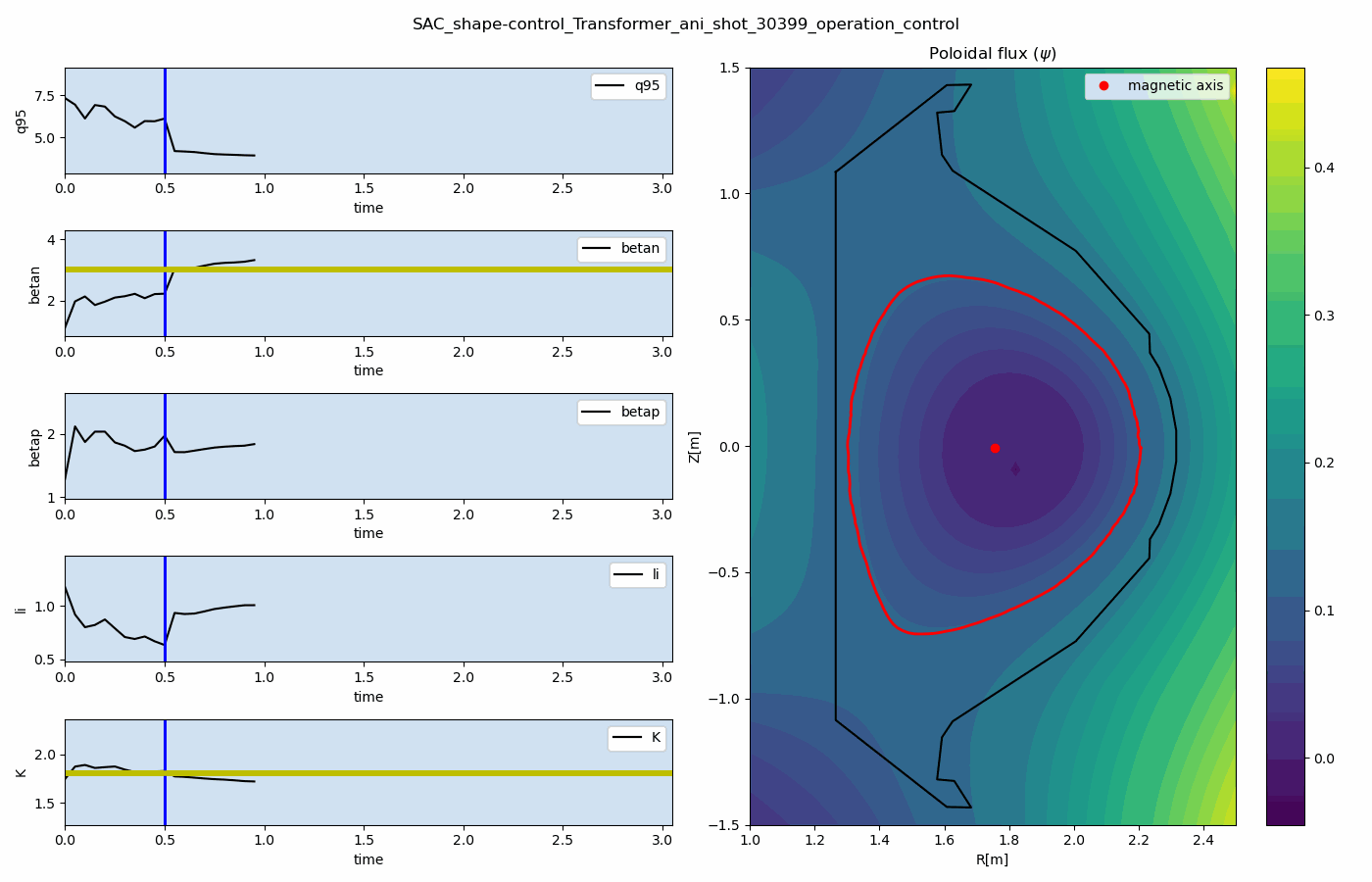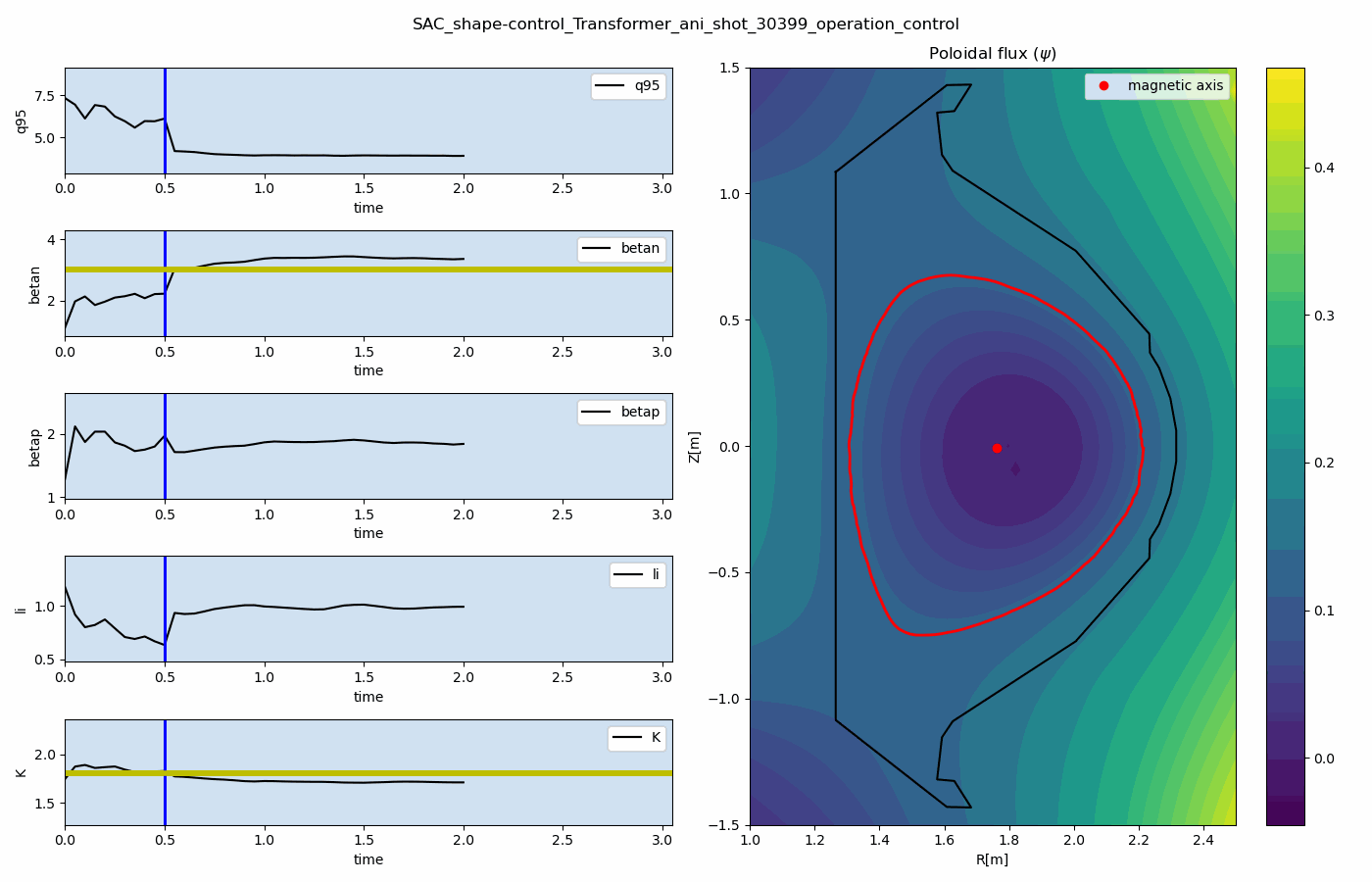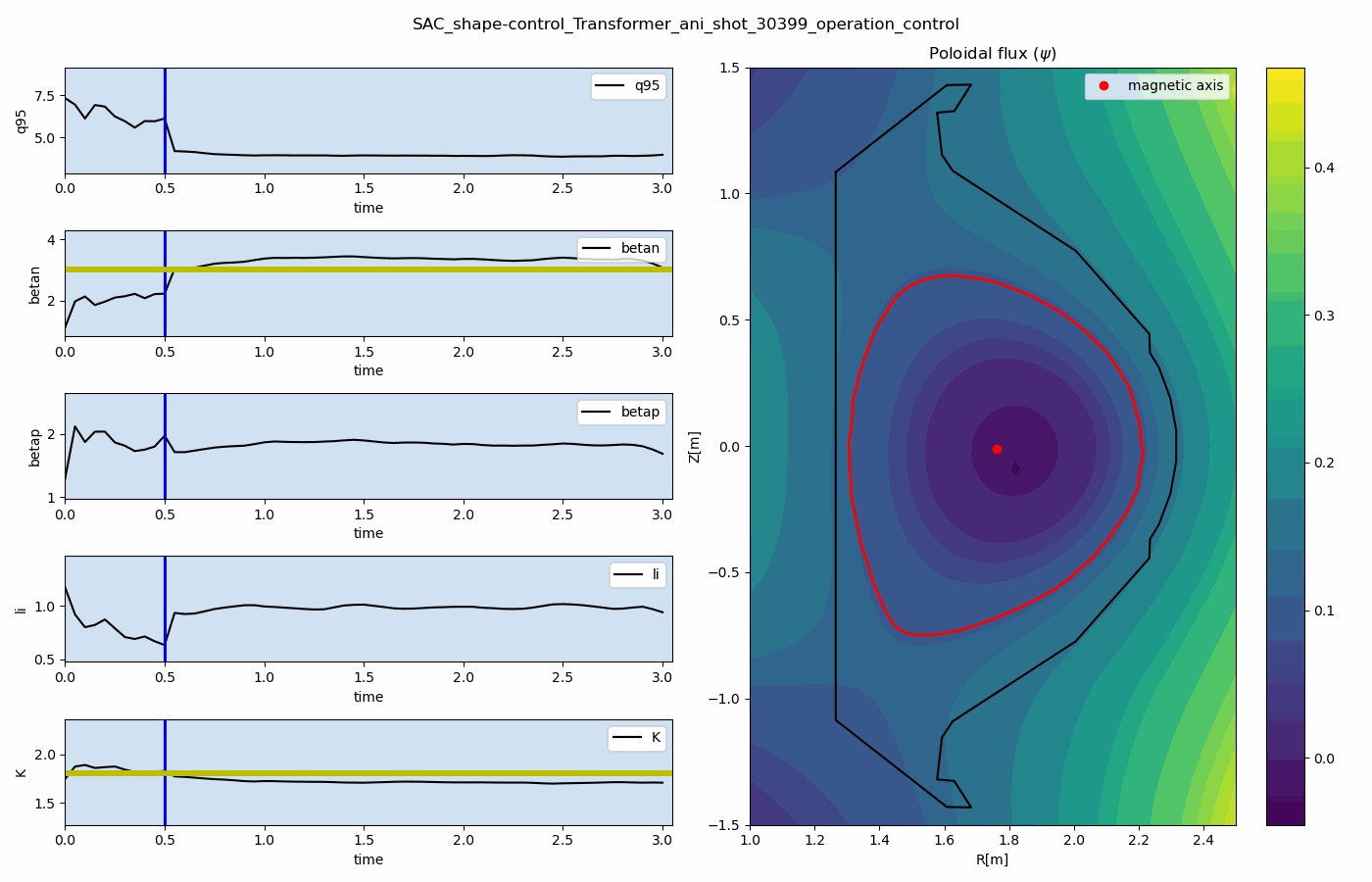
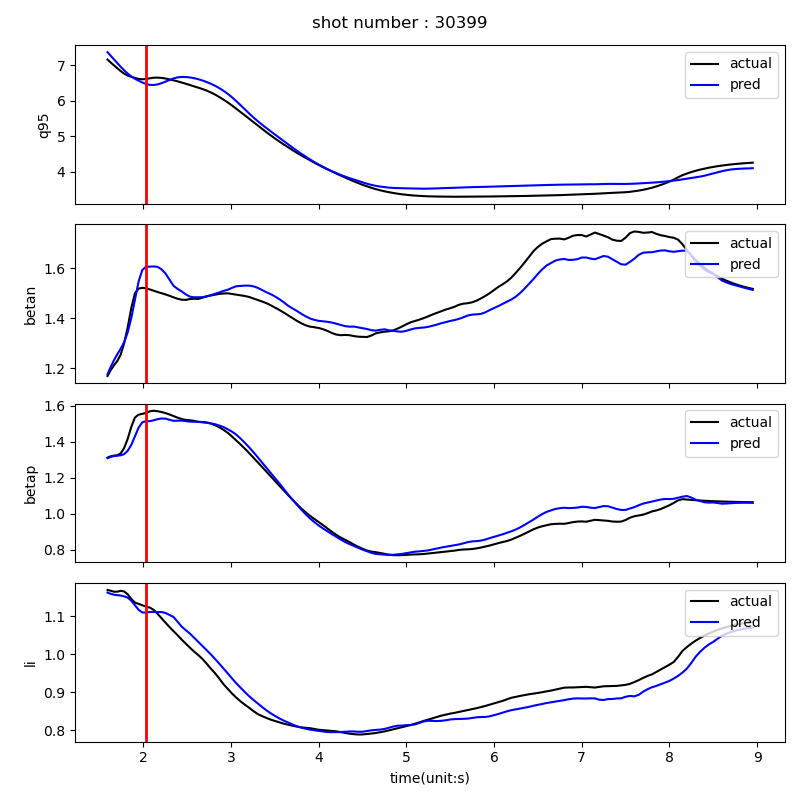
The main result is that a single reinforcement-learning agent can learn to control multiple plasma quantities, such as poloidal beta and safety factor, toward target values simultaneously.
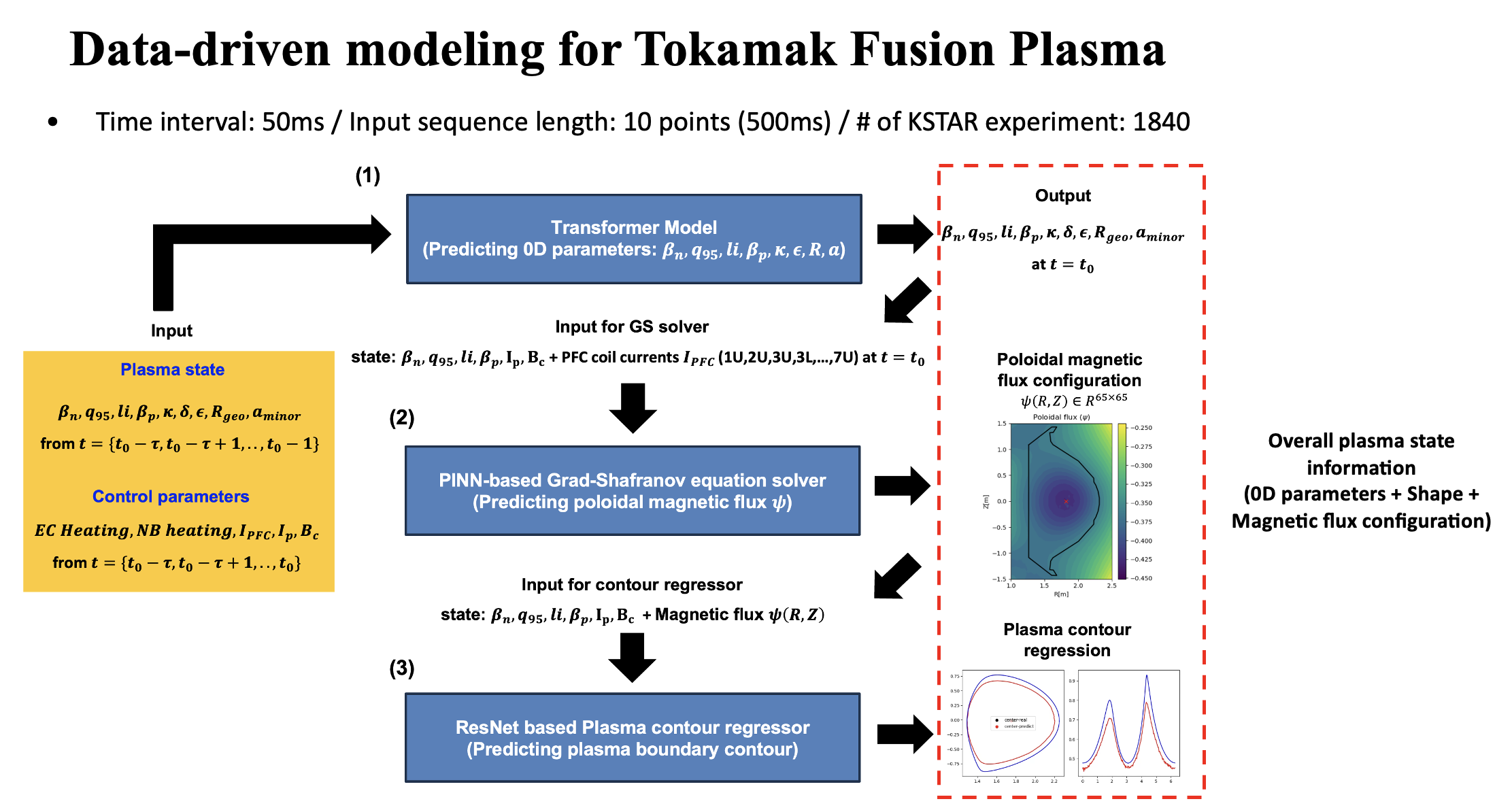
Building the Data-Driven Plasma Simulator
A key part of this framework is the construction of a data-driven tokamak simulator. The simulator is not a single neural network, but a combination of several modules that represent different parts of the plasma response.
The simulator consists of three main components:
- A Transformer-based time-integration model for predicting the next-step evolution of 0D plasma parameters.
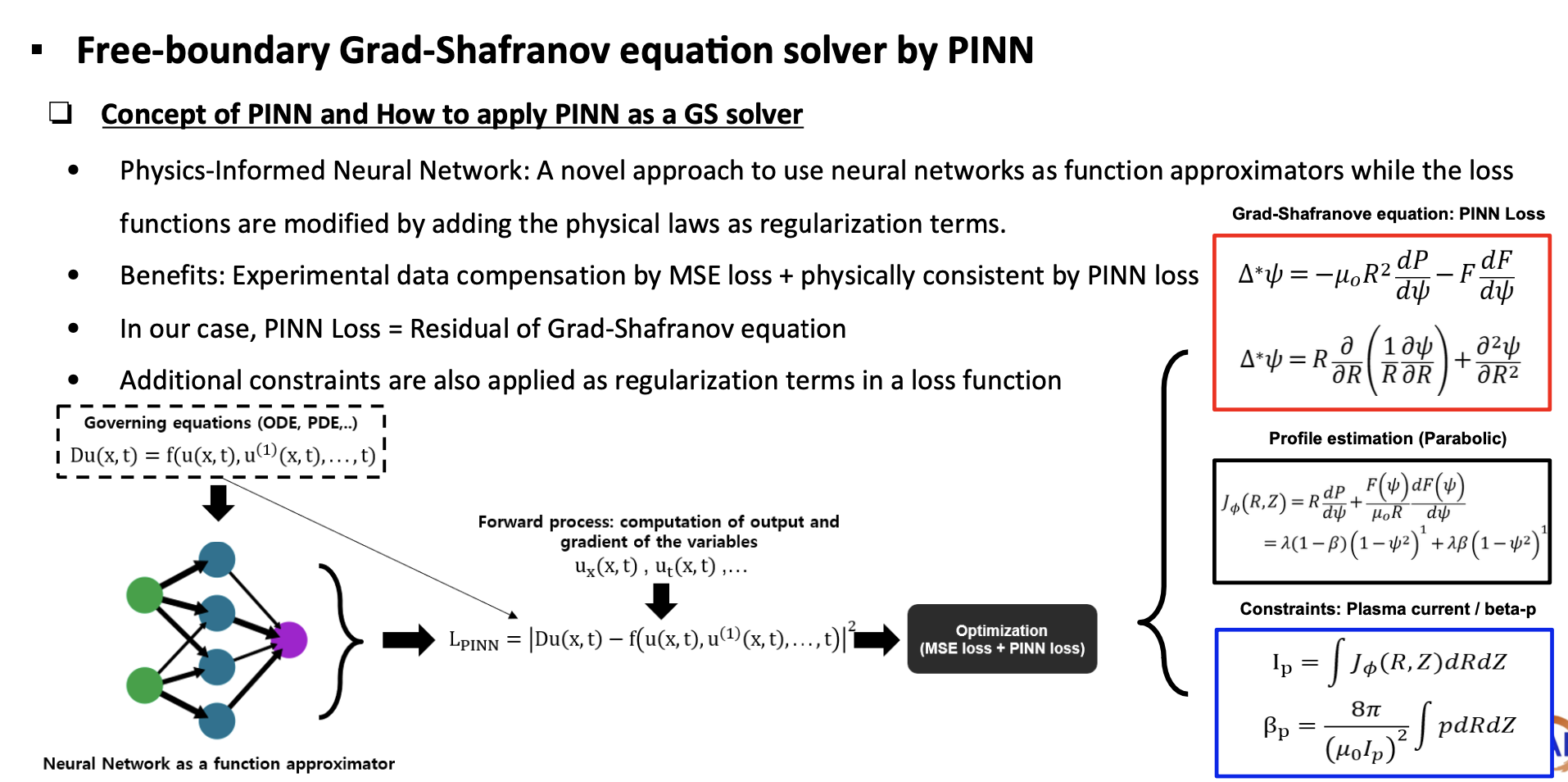
- A Physics-Informed Neural Network-based Grad-Shafranov solver for reconstructing the magnetic flux.
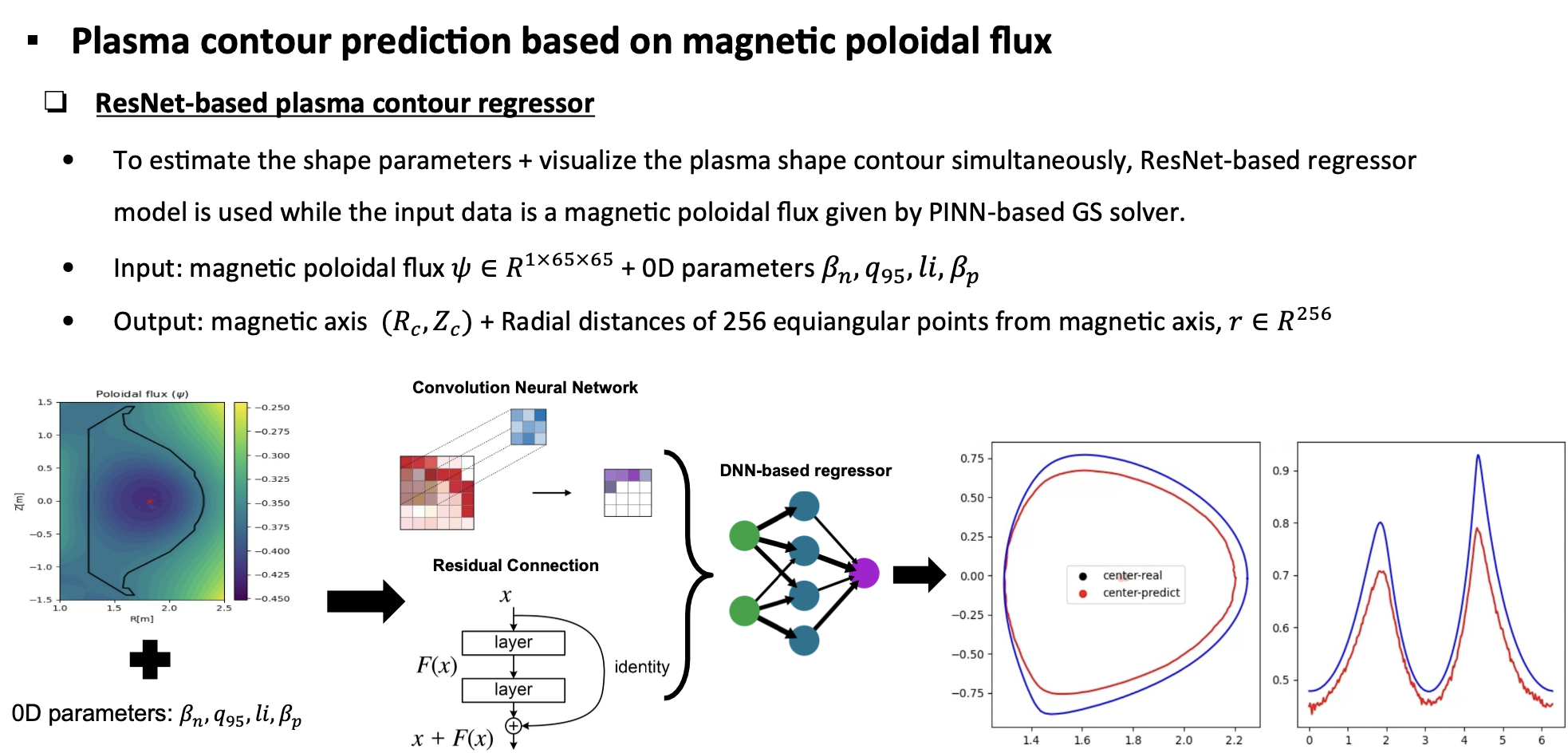
- A plasma boundary identification model for estimating the plasma boundary.
These modules are combined to reconstruct the plasma equilibrium and provide state information to the reinforcement-learning controller.
The Grad-Shafranov equation plays an important role in describing tokamak equilibrium. In this work, a PINN-based Grad-Shafranov solver is used to estimate the poloidal magnetic flux. Since the framework can also estimate pressure and current profiles, it provides a possible foundation for future profile-control studies.
A separate boundary-estimation model is used to identify the plasma boundary. This provides a stable way to visualize and track the plasma shape compared with conventional contour-based methods.
Representative prediction and control results are shown below. These results demonstrate how the data-driven simulator and reinforcement-learning controller can be combined for multi-target plasma operation control.
From Tokamak Operation to Kinetic Instability Suppression
The second direction studies a more fundamental kinetic plasma-control problem: suppressing the bump-on-tail instability in an electrostatic plasma.
The bump-on-tail instability is a classical example of wave-particle interaction. When a population of high-energy electrons is added to a background thermal plasma, the velocity distribution develops a bump in its high-velocity tail. Under the right conditions, this bump transfers energy from particles to plasma waves. As a result, the electric field grows, unstable Fourier modes appear, and the phase-space distribution becomes increasingly mixed.
In physical terms, the instability converts ordered beam energy into growing wave energy. From a control point of view, the goal is to interrupt this energy transfer before the unstable mode becomes dominant.
Modeling the Electrostatic Plasma
The kinetic plasma is modeled by the one-dimensional Vlasov-Poisson equation. This equation describes the evolution of the electron distribution function in phase space. The electric field is obtained self-consistently from the charge density through Poisson’s equation.
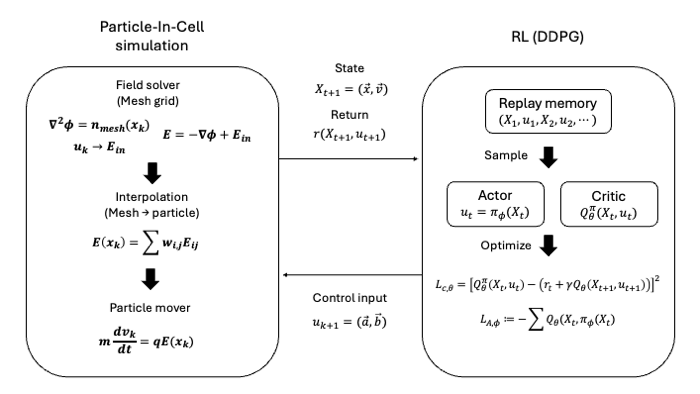
For numerical simulation, the plasma is discretized using the Particle-In-Cell method. In this approach, the distribution function is represented by many computational particles. The particles move according to the electric field, while the electric field is computed on a mesh from the particle density.
To suppress the instability, an external electric field is introduced as a control input. This control field is parameterized by a finite number of Fourier modes. The reinforcement-learning controller does not directly choose the entire field at every point in space. Instead, it learns the time-dependent coefficients of the external electric field.
This gives the controller a physically interpretable action space: it learns how to apply structured electric-field perturbations that counteract the unstable plasma response.
Optimal Control Viewpoint
The instability-suppression problem can be formulated as an optimal control problem. The objective is to reduce the electric-field energy associated with the instability while also penalizing excessive control input.
This reflects a natural trade-off. A controller could suppress the instability by applying a very strong external field, but such a strategy would be inefficient and physically undesirable. A useful control policy should suppress the wave growth with reasonable control effort.
In principle, the optimal feedback control law can be characterized by the Hamilton-Jacobi-Bellman equation. However, directly solving the HJB equation is infeasible for this system because the plasma state is high-dimensional and nonlinear.
This motivates the use of reinforcement learning as an approximate dynamic programming method. The value function and policy are approximated through data generated by interaction with the PIC simulation.
Reinforcement Learning Controller
The controller is trained using Deep Deterministic Policy Gradient, an actor-critic reinforcement-learning algorithm for continuous control. The actor network maps the plasma state to the external-field coefficients, while the critic network estimates the value of the state-action pair.
In each simulation step:
- The Particle-In-Cell solver advances the plasma state.
- The reinforcement-learning agent observes the particle positions and velocities.
- The actor network outputs the external electric-field coefficients.
- The controlled electric field modifies the particle dynamics.
- The reward evaluates whether the electric-field energy and control effort are reduced.
Through this interaction, the controller learns a feedback policy that applies an external electric field to suppress the unstable mode.
What Happens Without Control?
Without control, the initially perturbed plasma exhibits growth of the unstable Fourier mode. In the bump-on-tail case considered here, the dominant unstable mode is associated with the initially imposed perturbation. During the early linear phase, the electric-field spectrum grows as energy is transferred from high-energy particles to the wave.
This behavior is visible in the Fourier spectrum of the electric field. The uncontrolled case shows strong growth and accumulation of spectral energy near the unstable mode. As the instability develops further, nonlinear effects produce saturation, oscillation, and phase-space mixing.
What Changes with Optimal Control?
With the learned control policy, the unstable mode is significantly reduced. The controller applies a time-dependent external electric field that counteracts the resonant amplification of the unstable mode.
The comparison between uncontrolled and controlled spectra shows the main effect clearly. In the uncontrolled case, the unstable mode grows strongly. In the controlled case, the corresponding mode remains much smaller, and the electric-field energy does not experience the same instability-driven growth.
Fourier spectrum of the electric field over time
| Without control | Optimal control with DDPG |
|---|---|
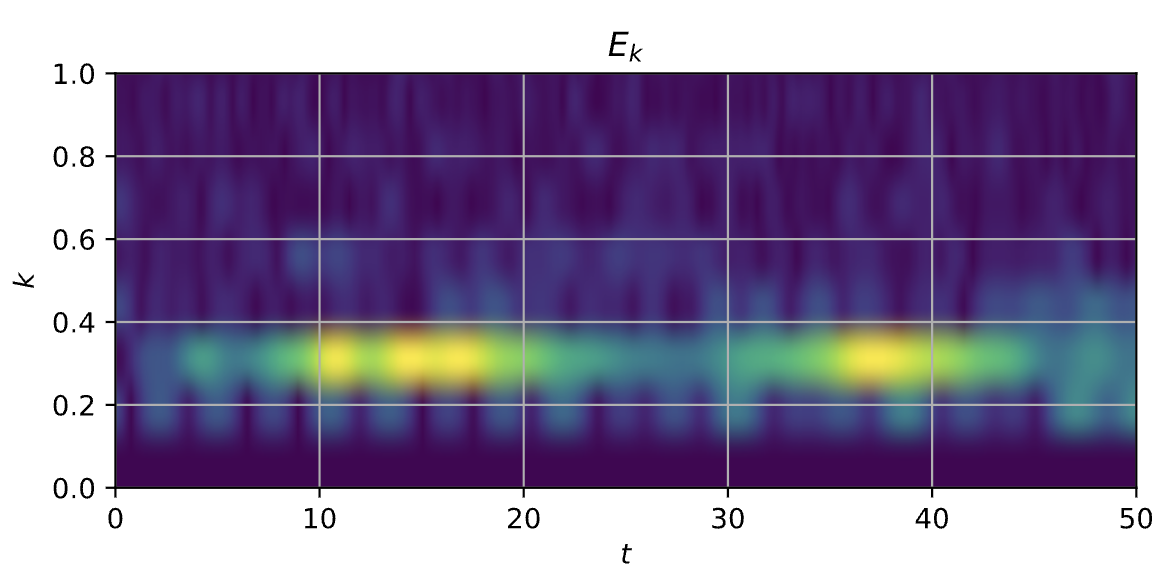 | 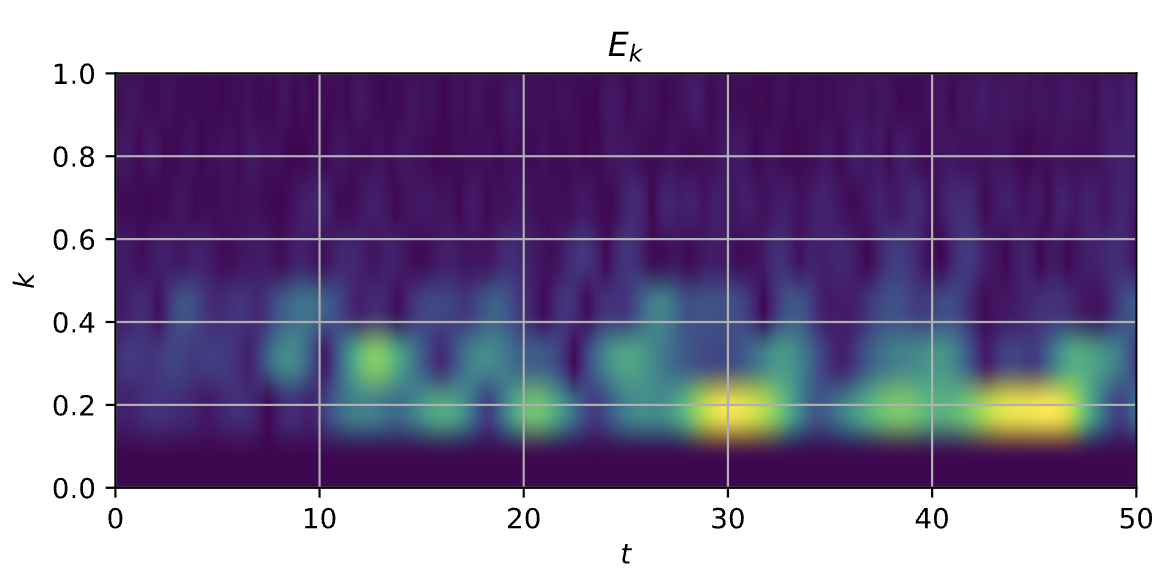 |
The learned policy does not simply eliminate all dynamics. Instead, it redistributes the spectral response in a way that prevents the resonant unstable mode from dominating. The simulation results show that the controlled system has weaker phase-space mixing, reduced electric-field growth, and a much smaller estimated linear growth rate.
In the final project study, the estimated linear damping/growth-rate comparison showed a substantial reduction under control:
| Case | Estimated rate |
|---|---|
| Without control | γL = 0.00557 |
| Optimal control | γL = 0.00034 |
This indicates that the learned external electric field effectively suppresses the instability growth.
Interpretation
The central observation is that reinforcement learning can discover a feedback strategy that acts directly on the instability mechanism. The bump-on-tail instability grows because particles transfer energy to waves through wave-particle resonance. By applying a learned external electric field, the controller modifies the plasma response before the unstable mode grows too strongly.
In this sense, the controller behaves like a data-driven approximation of an optimal feedback law. It does not require an explicit analytical solution of the high-dimensional HJB equation. Instead, it learns an effective control strategy through repeated interaction with the kinetic plasma simulation.
This result is encouraging because it suggests a possible route toward learning-based control of more complex plasma instabilities. The present example is one-dimensional and electrostatic, but it captures an important mechanism: instability growth through kinetic wave-particle interaction.
Outlook
The two projects described here address plasma control from complementary viewpoints.
The tokamak-control project focuses on macroscopic plasma operation. It asks how a data-driven simulator can be combined with multi-objective reinforcement learning to guide plasma parameters toward desired operational targets.
The instability-suppression project focuses on kinetic plasma dynamics. It asks whether reinforcement learning can find an external-field control policy that suppresses wave growth in a Vlasov-Poisson plasma.
Together, these studies support a broader research direction: developing intelligent control frameworks that combine plasma physics, data-driven modeling, and optimal control. Such methods may help design plasma scenarios that are not only high-performing, but also stable, robust, and efficient.
Publications and Presentations
Tokamak Plasma Operation Control
Jinsu Kim.
“Tokamak Plasma Operation Control using Multi-Objective Reinforcement Learning in KSTAR”
International Fusion Plasma Conference 2023.
Poster
Optimal Control for Instability Suppression
Jinsu Kim.
“Optimal Control for Instability Suppression in an Electrostatic Plasma with Reinforcement Learning”
Draft